Es gibt zahlreiche Identifizierungen für Menschen (Personalausweis, Führerschein, Bankkarte, Kopierkarte, Bootsführerschein, Rentenversicherungsnummer, usw.). Auch Waren werden oft mit Hilfe von Nummer identifiziert (ISBN bei Büchern, Netzkartennummer, Etikettierungen, usw.). Hier eine Übersicht als Blockbild:
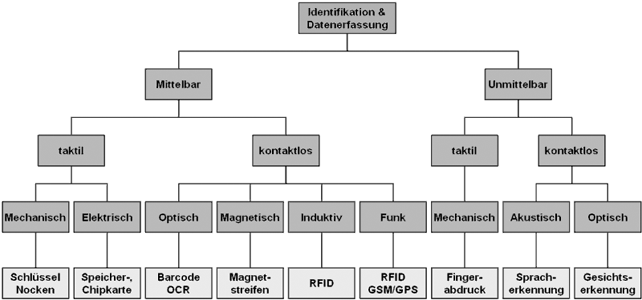
Alle von Software und/oder Hardware interpretierbaren Daten sind maschinenlesbar. Die maschinelle Identifizierung von Produkten wird in der Produktion, Qualitätssicherung, Betriebsdatenerfassung, Organisation, Versand und Handel verwendet.
Beispiele für Maschinenlesbarkeit: Laufzettel für Materialfluß, Lieferschein, Rechnung, Lagerzettel, Ausweise, Personalausweise, Kfz-Kennzeichen, Etiketten, Geldscheine, Konsumwaren, ISBN, usw.
Es werden optische (z.B. CCD - Kamera, He - Ne - Scanner), magnetische (z.B. Induktionsschleife), mechanische (Hebel) und elektro-mechanische (z.B. elektrischer Kontakt) Systeme eingesetzt. Die automatische Ablesung von gedruckten Daten ermöglicht z.B.
- die Erstellung der (komplette) Dokumentation im Lager und Versandwesen
- die automatische Steuerung des Transport- und Lagersystems
- die permanente Inventur und Bestandsüberwachung
Für die automatische Bearbeitung von Material- und Informationsflüssen (Paket, Palette, Container, Gitterbox, usw.) werden automatische Merkmalerfassungen, Klassifizierung, Identifizierung und auswertende Verknüpfung benötigt.
Übersetzungen, Computerlinguistik https://de.wikipedia.org/wiki/Kategorie:Computerunterstützte_Übersetzung
Multilinguale Bedienungsbeschreibungen von Geräten braucht Terminologiedaten ( DB ) für vielsprachige Texte, die untereinander ausgetauscht werden können. In ähnlicher Weise verwenden multilinguale Softwaresystemen für die Beschreibung der Diesplay-Texte von Applikationen XML-basierte Auszeichnungssprachen. TBX = TermBase eXchange ist ein Industriestandardformat für den Austausch von Terminologiedaten. TM (Translation Memory) speichert Ausgangs- und Zielsprachensegmente, die paarweise in einer Datenbank abgespeichert werden und die Übersetzungseinheit bilden. TMX (Translation Memory eXchange) ist ein offenes XML-Format für Terminologiedaten. de.wikipedia https://de.wikipedia.org/wiki/TermBase_eXchange MS https://www.microsoft.com/de-de/language/Terminology https://www.microsoft.com/de-de/language/Toolbox
Nachfolgend einige Identifikationssysteme und deren Synonyme. Siehe z.B. de.wikipedia: Abbreviatur ( lat./ital. abbreviatura = Abkürzung, abgekürzte Schreibweise)
ISBN (Bücher, Karten usw.) – 10 / 13 Stellen, standardisiert in ISO 2108:2005, International standard book number ISMN (Musik), standardisiert in ISO 10957:1993, International Standard Music Number ISRC (Musik), standardisiert in ISO 3901:2001, International Standard Recording Code ISSN (Zeitschriften u. Ä.) – acht Stellen, standardisiert in ISO 3297:1998 International Standard Serial Number PZN (Medikamente) EPC Weltweit überschneidungsfreie Identifikationsnummer zur Kennzeichnung von Objekten wie z. B. Artikeln. Während ein EAN einen Artikel nur der Art nach identifiziert (z. B. Cola-Dose 0,33 L), kann über einen EPC durch einen zusätzlichen serialisierten Nummernteil jeder einzelne Artikel unterschieden werden (jede Cola-Dose ist von jeder anderen unterscheidbar). Im EPC sind in der Regel die EAN-Nummernsysteme wie EAN (international: GTIN) für Artikel, NVE (SSCC) für Transporteinheiten und GRAI für Mehrwegtransportbehältnisse verschlüsselt. Um festzustellen, welches Nummernsystem im EPC verschlüsselt ist, enthält er hierzu zusätzlich einen Header. Über diesen Header kann dann vom RFID-Schreib-/Lesegerät gezielt auf bestimmte EPC zugegriffen werden. Die für den EPC zulässige RFID-Technologie wurde wie der EPC selbst von EPCglobal standardisiert. Nach dem Standard EPC Gen 2, sind nur solche RFID-Transponder für die Speicherung eines EPC zugelassen, die im Frequenzbereich um 900 MHz (UHF) arbeiten. VIN (Fahrzeuge), standardisiert in ISO 3779:1983, Vehicle identification number WMI (Fahrzeug-Hersteller), standardisiert in ISO 3780:1983, World Manufacturer Identifier code WPMI (Fahrzeug-Teile-Hersteller), standardisiert in ISO 4100:1980, World Parts Manufacturer Identifier code ISIN Internationale Wertpapierkennnummer (International Securities Identification Number) IMEI (Mobiltelefone) International Mobile Equipment Identity
RFID bedeutet Radio Frequency Identification (etwa "Identifikation per Funk") und kann
für die automatischen Identifizierung von Gegenständen und Lebewesen eingesetzt werden.
Für die automatische Bearbeitung von Material- und Informationsflüssen
(Paket, Palette, Container, Gitterbox, usw.)
werden automatische Merkmalerfassungen, Klassifizierung, Identifizierung
und auswertende Verknüpfung benötigt.
Hier einige Links:
wikipedia: Radio_Frequency_Identification
,
Thomas Finke, Harald Kelter: Abhörmöglichkeiten der Kommunikation
zwischen Lesegerät und Transponder am Beispiel eines ISO14443-Systems
,
Radio Frequency Identification (.pdf-Dias)
,
RFID-Quiz: strom-online.ch/rfid_infos
,
strom-online.ch/rfid_interaktiv
,
strom-online.ch/rfid_quiz
Auf einem Markierungsbeleg (Papier) wird an definierten Rasterpositionen aus der Gesamtmenge die zutreffende Alternative (z.B. mit Bleistift) angestrichen. Die Markierungshilfen (vorgedruckte Felder) werden in eine "Blindfarbe" (z.B. gelb, rot, orange, hellblau, grün) gedruckt und von der automatischen Erfassungseinrichtung ignoriert.
|
|
|---|
Durch Ankreuzen von Positionen in einer "1 aus 10" - Tabelle kann die Zahl 243.8 wie folgt markiert werden:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 100.0 | [ ] | [ ] | [X] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | Gelesen 200 |
| 10.0 | [ ] | [ ] | [ ] | [ ] | [X] | [ ] | [ ] | [ ] | [ ] | [ ] | Gelesen 40 |
| 1.0 | [ ] | [ ] | [ ] | [X] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | Gelesen 3 |
| 0.1 | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [X] | [ ] | Gelesen 0.8 |
Die Zahl 243.8 kann mit dem BCD - Code dargestellt werden:
| 1 | 2 | 4 | 8 | ||
|---|---|---|---|---|---|
| 100.0 | [ ] | [X] | [ ] | [ ] | gelesen 200 |
| 10.0 | [ ] | [ ] | [X] | [ ] | gelesen 40 |
| 1.0 | [X] | [X] | [ ] | [ ] | gelesen 3 = 1 + 2 |
| 0.1 | [ ] | [ ] | [ ] | [X] | gelesen 0.8 |
Dieses Beispiel benötigt nur 40 % der Fläche von "1 aus 10". Die handschriftlichen Eintragungen dauern länger und es treten leicht Fehler auf.
Eine automatische Texterkennung (Optische Zeichenerkennung; OCR = Optical Character Recognition) kann Texte auf einer gedruckten Vorlage scannen und in einen Zeichencode wandeln. Beispiele sind:
- Für Registrierkassen werden Journal - Streifen (einige cm Breite) verwendet, die mit numerischen Zeichen und Sonderzeichen bedruckt werden.
- Im Bankwesen werden Belege (meistens DIN A 6) mit maschinell lesbaren Zeilen verwendet.
- Im Druckereiwesen werden maschinenlesbare Seiten mit alphanumerischen Informationen verwendet.
Maschinenlesbare Schriften (Klarschrift) benutzen Buchstaben-, Ziffern- und Sonderzeichen. Maschinenlesbare Schriften können mit einem Klar - Schrift - Leser automatisch dekodiert werden. Als Datenträger wird (hochwertiges Papier, 0.1 .. 0.2 mm Dicke) verwendet. International sind genormt:
- Die OCR - A - Schrift (optical character recognition) besteht aus stark stilisierte lateinischen Buchstaben ohne Kleinbuchstaben, die eine einfache optische Zeichen - Erkennung ermöglichen.
- OCR - B - Schriften sind für Menschen besser lesbar und enthalten auch Kleinbuchstaben. Die maschinelle Decodierung ist aufwendiger als bei OCR - A - Schriften.
Jedem Geldschein (Deutschland, DM-Zeiten) wird eine eindeutige Kennung zugeordnet mit folgendem Aufbau:
- zwei Buchstaben
- sieben Ziffern
- ein Buchstabe
- eine Prüfziffer.
Diese Gestaltung gilt für jede einzelne Geldscheinsorte. Die erstmögliche Numerierung ist AA0000001A+Prüfziffer. Dann werden die sieben Ziffern bis jeweils 9 hochgezählt. Nunmehr wird der letzte Buchstabe verändert und die Ziffernfolge beginnt von vorne usw.
Im folgenden verändert sich der mittlere und zuletzt der erste Buchstabe . Für die Buchstaben sind nur zehn bestimmte möglich, nämlich A, D, G, K, L, N, S, U, Y und Z. Sind alle Möglichkeiten ausgereizt, beginnt die Numerierung wieder am Anfang.
Die Strichcode - Entwicklung (Balkencode, Barcode) ist mit der Entwicklung der Computer verknüpft. Ein Strichcode (Balkencode, Barcode) erlaubt eine automatische, schnelle, sichere Computer - Eingabe. Einige Jahreszahlen:
- 1949 erstes Barcode - Patent in USA
- 1967 Automatisierung von Warenflüssen
- 1968 Code2/5 (Fa. Identicon Corporation)
- 1972 Code 2/5 interleaved, Codabar
- 1974 Code 39
- 1976 Code EAN (European Article Numbering)
- 1981 Code 128, Code 93
- 1988 Code 49
Ein Strichcode ist leicht zu erstellen und mit einfachen Leseeinrichtungen sicher zu decodieren. Im Lebensmittelbereich wird in Europa der EAN-Code verwendet (z.B. auf Tuben, Kartons, Flaschen, Dosen). Im medizinisch - klinischen Bereich wird CODABAR verwendet.
Die meisten Strichcodes basieren auf dem Binärprinzip mit einer Anzahl von schmalen / breiten Strichen / Lücken. Die Ablesung erfolgt optisch. Unterschiedliche Reflexionen von dunklen und hellen Stellen ergeben eine Sequenz von elektrischen Signalen.
Die folgenden Barcodeformate werden 2016 verwendet: 1D barcodes: EAN-13, EAN-8, UPC-A, UPC-E, Code-39, Code-93, Code-128, ITF, Codabar 2D barcodes: QR Code, Data Matrix, PDF-417, AZTEC

EAN bedeutet "European Article Number". Die Gesellschaft zur Rationalisierung des Informationsaustausches zwischen Handel und Industrie (CCG = Centale für Organisation) wurde 1974 gegründet und 1977 wurde die Artikelnumerierung EAN in der Bundesrepuplik eingeführt. EAN erfaßt alle im Groß- und Einzelhandel angebotenen Gebrauchs- und Verbrauchsgüter.
- EAN (European Article Numbering)
- IAN (Internationale Article Numbering)
- JAN (Japanese Article Numbering)
- UPC (Universal Product Code, Amerika)
EAN ist eine Abkürzung für Europäische Artikel-Nummerierung. Der EAN - Strichcode dient der Rationalisierung der Warenwirtschaft im Handel und der Artikelidentifikation im elektronischen Geschäftsverkehr.
Es wird ein 13 stelliger EAN-Code benutzt (seltener 8 Stellen). Das sichtbare Strich - Code - Feld besteht aus dem Strichcode und einer OCR - B - Klar - Schriftzeile. Der 13 Ziffern Code enthält
- Länderpräfix (0, 1), 40 bis 43 stehen für Deutschland
- Teilnehmer, Herstellernummer (2, 3, 4, 5, 6),
- individuelle 5 stellige Artikelnummer des Herstellers oder Lieferanten (7, 8, 9, 10, 11). Diese Nummer legt der Hersteller fest.
- Prüfziffer (Modulo 10 mit Gewichtung 3)
Für Waren ist die Artikelnummern der Schlüssel für die Zuordnung. Andere Zuordnungen zu Waren sind: wirtschaftliche Informationen, Spezialnumerierungen, Bezeichnungen, Warengruppierungen, Lieferanten, Konditionen, Preise.
ISBN ist eine Abkürzung für International Standard Book Number . ISBN wird für eine international gültige Bücher-Numerierung verwendet. Die Internationale Standard-Buchnummer ist ein weltweit-eindeutiges Identifikationsmerkmal für jedes Buch. jedes Buch wird damit unverwechselbar.
Eine ISBN wird dauerhaft einer einzelnen, monographischen Verlagspublikation zugewiesen, unabhängig davon, ob es sich um ein gedrucktes Buch oder einen elektronischen Datenträger handelt. Nur Werke mit ISBN finden Eingang in das Verzeichnis Lieferbarer Bücher (VLB), der umfassendsten Datenbank für den Buchhandel und die zentrale Marketingplattform der Verlagsbranche.
Nach ISBN folgt eine 10-stelligen Zahl, die in 4 Gruppen aufgeteilt ist. Diese Gruppen werden entweder durch einen Bindestrich oder Leerzeichen getrennt. Die Gruppen bauen sich wie folgt auf:
- Land: "3" steht z.B. für alle deutschsprachigen Länder (Deutschland, Österreich, Schweiz)
-
Verlag: Große Verlage erhalten kleine Verlagsnummern und große
Buchnummern,
kleine Verlage erhalten längere Verlagsnummern und kleinere Buchnummern - Buchnummer: verlagsinterne Nummer für das jeweilige Buch
- Prüfziffer: Aus allen anderen Ziffern wird eine Kontrollzahl berechnet.
Im Buchhandeln werden die ISBN oft per Telefon, Fax, usw.. übertragen. Zum Prüfen der ISBN wird
die 1. Ziffer mit 10 multipliziert,
die 2. mit 9 multipliziert,
die 3. mit 8, usw. ... multipliziert
Alle Produkte werden addiert.
Die ISBN ist gültig, wenn das
Ergebnis mod 11 = 0ist.
Bislang bestand die ISBN aus vier Elementen: der Gruppennummer, der Verlagsnummer, der Titelnummer und der Prüfziffer.
Beispiel: Lautet die ISBN z.B. 3-8322-5591-5, so steht die 3 für den deutschsprachigen Raum (die Gruppennummer kann neben Sprachbereichen auch Länder oder geographische Regionen kennzeichnen). Die 8322 identifiziert den Verlag und die 5591 eine bestimmte Publikation oder Ausgabe dieses Verlags. Die 5 ist die Prüfziffer, die nach einem festgelegten arithmetischen Prozess ermittelt wird und das Erkennen von Tippfehlern in einer ISBN ermöglicht.
Ab dem 1.1.2007 wird die bisherige Internationale Standard-Buchnummer (ISBN) durch eine 13-stellige ISBN abgelöst.
Bei der neuen ISBN-13 wird nun zusätzlich das Präfix 978 vorangestellt. Dieses Präfix ist innerhalb der EAN (European/International Article Number) für Verlagsprodukte vorgesehen (Reserve 979) und wird nun zum festen Bestandteil der ISBN. Dadurch ändert sich auch die Prüfziffer.
Bei den alten Ägyptern und Römern gab es festgelegte Codes für die Zahlendarstellung. Es wurde ein Zehnersystem benutzt, bei dem eine Zahl als Addition von Symbolen für die Zahlen 1, 10 und 100 geschrieben wird. Zur Verringerung des Schreibaufwandes (z.B. für 99 ...) erweiterten die Römer diese Idee und verwendeten die folgenden Zeichen:
| Zeichen: | I | V | X | L | C | D | M |
| Dezimalwert: | 1 | 5 | 10 | 50 | 100 | 500 | 1000 |
Falls die Ziffern der Größe nach geordnet aufgeschrieben werden, werden die einzelnen Werte zum Ergebnis addiert. Falls eine Ziffer vor einer größeren steht, dann wird ihr Wert vom Ergebnis subtrahiert.
Beispiele: XCIII ergibt die Zahl (1*100 - 1*10 + 3*1) = 93. CXXXIV ergibt die Zahl (1*100 + 3*10 + 1*5 - 1*1) = 134.
Die Schreibweise von römischen Zahlen ist zunächst nicht eindeutig.
Z.B. kann 14 geschrieben werden durch VVIIII oder XIV oder XIIII usw.
Deshalb wurden die folgenden Regeln eingeführt. In einer Zahl dürfen die Zeichen:
- I, X und C nur maximal 3 mal vorkommen
- V, L und D nur maximal einmal vorkommen
- M darf beliebig oft vorkommen
Auf die alten Ägyptern geht das "Halbiere und Verdopple-Verfahren" zurück, das heute (wegen der hohen Geschwindigkeit) als Micro-Code im Assembler für die Multiplikation von ganzen Zahlen verwendet wird.
| Zahlenbeispiel | Pseudo-Code | Assembler-Programm |
43* 38 = =21* 76 + 38 =10* 152 + 76+38 = 5* 304 + 0+76+38 = 2* 608 + 304+0+76+38 = 1*1216 + 0+304+0+76+38 = 0*2432 + 1216+0+304+0+76+38 |
c:=43;
b:=38;
a:= 0;
while (c > 0) {
if(c ungerade){ a := a + b;}
c := c shr 1; //verdopple c
b := b shl 1; //int-Div durch 2
}
// Ergebnis ist in a
|
mov cx,43 mov cx,38 mov ax,0 bis_null: shr cx,1 jnc ohne_add add ax,bx jnc falsch ohne_add: jz mul_is_ok shl bx,1 jnc bis_null falsch: mov ax,offffh mul_is_ok:// Erg in ax |
Das Internationales Flaggenalphabet und Signalcodes dienen der visuellen Verständigung zwischen Schiffen. Einzeln gesetzte (zusätzliche) Flaggen haben eine spezielle Bedeutung, wie z.B.: A für Taucherarbeiten, B für Gefahrguttransport, L für Stoppen Sie!, Q für Zoll, usw.

Fahnen und Flaggen können Zeichen aber auch Symbole sein.
1832 hatte Samuel F. B. Morse auf einer Schiffahrt von Europa nach Amerika die Idee, einen auf Elektromagnetismus beruhenden Telegraphen zu bauen. Er entwickelte das erste Morsealphabet. Der Morse - Code benutzt Punkte ".", Striche "-" und Lücken. Der Morse - Code gehört auch heute noch zu jeder Funkerausbildung.
| Morse - Alphabet | ||||||||||||
| A | B | C | D | E | F | G | H | I | J | K | L | M |
| .- | -... | -.-. | -.. | . | ..-. | --. | .... | .. | .--- | -.- | .-.. | -- |
| N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| -. | --- | .--. | --.- | .-. | ... | - | ..- | ...- | .-- | -..- | -.-- | --.. |
Das bekannteste Beispiel des internationalen Morsealphabetes ist das
SOS-Not-Ruf-Signal: ···---···
Der Morse - Code ist nicht umkehrbar eindeutig, denn z.B. ergibt sich mit e =".", i = ". .", s = ". . .", n = "- . ", v = ". - ."
seen = ". . . . . - ." und ebenso eier = ". . . . . - ."
Fernschreiber ist ein schreibmaschinenähnlicher Drucktelegraf (Ein- und Ausgabe im Klartext), der als Sende- und Empfangsanlage arbeitet und als Blatt- oder Streifenschreiber ausgeführt ist. Der Fernschreiber arbeitet nach dem Start-Stop-Prinzip, das heißt, Sender, Empfänger und Drucker werden für jedes Zeichen in Gang gesetzt und wieder angehalten.
1880 erfand Jean Maurice Emile Baudot (1845-1903, französischer Telegrafiepionier) den Fernschreibcode Nr.1 (Baudot-Code) Die Schrittgeschwindigkeit Baud geht aus dem Namen Baudot hervor.
Fernschreiber-Codes entsprechen Binärsequenzen, die über Leitungen oder Funk übertragen werden. Durch ds Niederdrücken einer Taste sendet der Fernschreibsender eine charakteristische Gruppe von zugeordneten elektrischen Signalen. Bei der Übermittlung per Funk wird eine Hochfrequenzschwingung zwischen zwei Frequenzen variiert, wobei der einen 0, der anderen 1 zugeordnet wird.
Ein Zeichen wird mit 5 oder 7 Bits codiert. Ein solches Bitmuster repräsentiert Buchstaben, Zahlen und länderspezifische Sonderzeichen. Die 5-Bit Codierung ist im (Internationales Telegrafenalphabet Nummer 2, ITA2) festgelegt. Die 7-Bit Codierung ist im (Alphabet Nummer 3 und 5, gleich lange Schritte, Schrittgeschwindigkeit von 50 Bd Baud) festgelegt.
Nach Niederdrücken einer Taste sendet der Fernschreibsender eine für das zu übermittelnde Zeichen charakteristische Gruppe von elektrischen Signalen. Der Fernschreibcode hat für jedes Zeichen eine Kombination von fünf (Internationales Telegrafenalphabet Nummer 2) oder sieben (Alphabet Nummer 3 und 5) gleich langen "Schritten", mit einer Schrittgeschwindigkeit von 50 Bd (Baud).
Bei einem Fernschreiber werde Binärsequenzen über Leitungen oder Funk übermittelt. Bei der Funkübertragung entspricht 0 bzw. 1 einer bestimmten Hochfrequenz. Eine Bitfolge von 5 - 7 Bits kennzeichnet einen Buchstaben, Zahlen und länderspezifische Sonderzeichen.
Die einzelnen Codewörter sind im sogenannten ITA2 (Internationales TelegraphenAlpabet Nr. 2) festgelegt, welches in etwa einem verkürzten ASCII-Code entspricht.
Das 12-Punkte-System von C. Barbier wurde durch L. Braille verbessert und als Blindenschrift bezeichnet. Von hinten werden in das Papier punktförmige Erhebungen gedrückt, die mit den beiden Zeigefingern ertastet werden können. Die Blindenschrift besteht aus Prägepunkten, die ertastet werden können. Es kann die normale Vorlesegeschwindigkeit erreicht werden.
Bei der gebräuchlichen Blindenschrift besteht ein Zeichen aus 2 senkrechten Spalten mit jeweils 3 Punkten.
Beispiel:
W A L T E R B A C H M A N N

Oft wird in Deutschland die normale Punktschrift (6 Punkt Braille) verwendet. Diese Schrift ist nicht genormt. In der DIN 32982 ist die 8 Punkt Braille genormt, die beim PC verwendet wird.
Grundlage eines jeden Binärcodes ist ein sogenanntes Binäres System, d.h. ein System, in dem nur ausschließlich zwei gegensätzliche Zustände herrschen, zum Beispiel An/Aus, Wahr/Falsch, 5/0 Volt im Stromkreislauf oder 1/0 beim Binärcode. Die Basiseinheit des Binärcodes bildet das Bit, das den Wert 0 oder 1 annehmen kann. 8 Bits werden zu einem Byte zusammengefaßt. Einen solchen Dualismus kennt man auch aus Programmierung Datentyp BOOLEAN (nach Georg Boole, 1815-1864, engl. Logiker und Mathematiker).
Die Bedeutung eines Bitmusters muß festgelegt werden. Ein Bitmuster kann z.B. Zahlen, Bilder, Zeichen, Musik, Programmcode repräsentieren.
Im Dualsystem werden Zahlen ähnlich wie im Dezimalsystem durch Potenzen dargestellt, allerdings nicht zur Basis 10, sondern zur Basis 2.
| Dezimalsystem | Dualsystem | |||||||||||
| Potenz | 102 | 101 | 100 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 |
| Zahl | 2 | 6 | 7 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
|
Rech- nung |
2*102 + 6*101 + 7*100 = 2*100 + 6*10 + 7*1 = 267 | 1*28 + 0*27 + 0*26 + 0*25 + 0*24 + 1*23 + 0*22 + 1*21 + 1*20 = 256 + 8 + 2 + 1 = 267 | ||||||||||
Die Addition erfolgt im Dualsystem stellenweise mit Übertrag, die Multiplikation ist sogar noch einfacher:
10001001 110*101
+ 1000101 ----------------
-------------- 110
11001110 0
110
----------------
11110
Jeweils 4 Bit können mit einer Hez-Ziffer (0,1,2,..., D,E,F) dargestellt werden.
| Mit n Bits können 2n verschiedene Bitmuster gebildet werden | ||||||||||||||||
| Bin | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
| Dez | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 | 13 | 14 | 15 |
| Hex | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
Zahlen in wissenschaftlicher Notation bestehen aus Vorzeichen (Sign Bit) , Mantisse (Significant) und Exponent (Biased Exponent). Wir müssen daher bei en sehr genau zwischen der Von der Größe einer Gleitpunktzahl (Wert des Exponenten) ist die Darstellungsgenauigkeit (Anzahl der gespeicherten Ziffern) zu unterscheiden. Das Format von Gleitpunktzahlen ist in IEEE 754 (Floating Point Standard) festgelegt. Es gibt die Daten-Formate:
- Word Integer (Zweierkomplement, Bereich 104, Genauigkeit 16 Bit),
- Short Integer (Zweierkomplement, Bereich 109, Genauigkeit 32 Bit),
- Long Integer (Zweierkomplement, Bereich 1018, Genauigkeit 64 Bit),
- Packed BCD (Bereich 1018, Genauigkeit 18 Digits),
- Single Precision ( 8 Bit für Exponenten, Bereich 10+38; 24 Bits für Mantisse, Genauigkeit 24 Bit),
- Double Precision ( 11 Bit für Exponenten, Bereich 10+308; 53 Bits für Mantisse, Genauigkeit 53 Bit),
- Extended Precision ( 16 Bit für Exponenten, Bereich 10+-4932; 64 Bits für Mantisse, Genauigkeit 64 Bit).
Gleitpunktzahlen werden vielfältig benötigt (naturwissenschaftlichen, technischen Anwendungen, Grafik, numerische Mathematik, usw.). Wegen des Zeitbedarfes werden Fließkommaoperationen von Gleitpunktzahlen (engl. Floating Point Numbers) in digitalen Einheiten (Coprozessor) ausgeführt.
| Bitweise Darstellung einer double-Zahl | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 63 .. 56 | 55 .. 48 | 47 .. 40 | 39 .. 32 | 31 .. 24 | 23 .. 16 | 15 .. 8 | 7 .. 0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | 2 | 1 | 0 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 0 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| s | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wert = (-1)s * 2e-e0 * (normalisierte Mantisse) mit e = Exponent (-1022 ...1023), e0 := 1023 und 1 <= normalisierte Mantisse < 2
Beispiel:
dez 25678.34 =
= dez 2.567834*104 =
= bin 0110 0100 0100 1110.0101 0111 =
= bin 0110 0100 0100 1110. 0101 0111 =
(. um 14 Positionen verschieben, begrenzen der Mantisse auf 3 Byte:)
= bin 1.1001 0001 0011 1001 0101 11oo * 2dez 14
(e0+14 = dez 1023 + 14 = dez 1037 = bin 100 0000 1101)
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . |
| 4 | 6 | C | 8 | 9 | C | A | E | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||||||||||||||||||||||||||||||||||||||||||||||||
Zur besseren Übersicht wird bei der folgenden Code-Zusammenstellung anstelle von "0" ein Punkt "." geschrieben.
| Dez | 1 aus 10 | 2 aus 7 | 2 aus 5 |
Libaw - Craig |
BCD 8421 |
Stibitz 3Exz. |
Aiken 2421 |
White 5211 |
Glixon | Gray |
O´ Brien |
| 0 | .........1 | 1.....1 | ...11 | ..... | .... | ..11 | .... | .... | .... | .... | ...1 |
| 1 | ........1. | 1....1. | ..1.1 | ....1 | ...1 | .1.. | ...1 | ...1 | ...1 | ...1 | ..11 |
| 2 | .......1.. | 1...1.. | ..11. | ...11 | ..1. | .1.1 | ..1. | ..11 | ..11 | ..11 | ..1. |
| 3 | ......1... | 1..1... | .1..1 | ..111 | ..11 | .11. | ..11 | .11. | ..1. | ..1. | .11. |
| 4 | .....1.... | 1.1.... | .1.1. | .1111 | .1.. | .111 | .1.. | .111 | .11. | .11. | .1.. |
| 5 | ....1..... | .1....1 | .11.. | 11111 | .1.1 | 1... | 1.11 | 1... | .111 | .111 | 11.. |
| 6 | ...1...... | .1...1. | 1...1 | 1111. | .11. | 1..1 | 11.. | 1..1 | .1.1 | .1.1 | 111. |
| 7 | ..1....... | .1..1.. | 1..1. | 111.. | .111 | 1.1. | 11.1 | 11.. | .1.. | .1.. | 1.1. |
| 8 | .1........ | .1.1... | 1.1.. | 11... | 1... | 1.11 | 111. | 11.1 | 11.. | 11.. | 1.11 |
| 9 | 1......... | .11.... | 11... | 1.... | 1..1 | 11.. | 1111 | 1111 | 1... | 11.1 | 1..1 |
Bei einem Code mit dem konstanten Gewicht k ist die Anzahl der "1"-en immer gleich k. Wenn ein Wort aus n bits (Wortlänge) besteht, so können bk verschiedene Bitmuster gebildet werden. Der Binomial - Koeffizient BK ist
| BK (n , k) := n! / k! / (n - k)! |
Für einen "1 aus 10"-Code ergibt sich BK(10,1) = 10 und für "2 aus 5" ergibt sich BK(5,2) = 10.
Der Code für die Siebensegment - Anzeige ist kein k aus n Code.
Der Stibitz - Code heißt auch 3 - Excess - Code, weil die Zahl 3 auf den Binär - Code addiert wurde. Der Stibitz - Code ist redundant, weil zur Codierung einer dezimalen Ziffer 4 Bits verwendet werden.
| 3.Bit | 2.Bit | 1.Bit | 0.Bit | bin | dez | |
| setze Bit 1 | 1111 | - | ||||
| setze Bit 1 | ||||||
| setze Bit 0 | 1110 | - | ||||
| setze Bit 1 | ||||||
| setze Bit 1 | 1101 | - | ||||
| setze Bit 0 | ||||||
| setze Bit 0 | 1100 | 9 | ||||
| setze Bit 1 | ||||||
| setze Bit 1 | 1011 | 8 | ||||
| setze Bit 1 | ||||||
| setze Bit 0 | 1010 | 7 | ||||
| setze Bit 0 | ||||||
| setze Bit 1 | 1001 | 6 | ||||
| setze Bit 0 | ||||||
| setze Bit 0 | 1000 | 5 | ||||
| Wurzel | ||||||
| setze Bit 1 | 0111 | 4 | ||||
| setze Bit 1 | ||||||
| setze Bit 0 | 0110 | 3 | ||||
| setze Bit 1 | ||||||
| setze Bit 1 | 0101 | 2 | ||||
| setze Bit 0 | ||||||
| setze Bit 0 | 0100 | 1 | ||||
| setze Bit 0 | ||||||
| setze Bit 1 | 0011 | 0 | ||||
| setze Bit 1 | ||||||
| setze Bit 0 | 0010 | - | ||||
| setze Bit 0 | ||||||
| setze Bit 1 | 0001 | - | ||||
| setze Bit 0 | ||||||
| setze Bit 0 | 0000 | - | ||||
| 3.Bit | 2.Bit | 1.Bit | 0.Bit | bin | dez |
BCD ist eine Abkürzung für Binary Coded Decimal.
Eine Hexadezimale Ziffer(0, 1, 2, ..., 9, E, F) wird mit 4 Bit dargestellt.
Eine Dezimal - Ziffer (0, 1, 2, ..., 9) benötigt ebenfalls 4 bit (Tetrade, Nibble).
Der BCD - Code ist kein Minimalcode, weil von den 2^4 = 16 verschiedenen Bitmustern
lediglich 10 verwendet werden (Pseudo - Tetdraden).
Beispiel:
Die Dezimalzahl
19
7
hat die BCD - Darstellung
0001
1001 0111
.
Der Libaw - Craig - Code ist ein einschrittiger Code.
Der 2/5-Code wurde 1968 von der Fa. Identicon Corporation entwickelt und kommt in Warenhäusern, auf Flugtickets und Fototaschen zum Einsatz. Beim 2/5-Code werden lediglich die Striche codiert. Lücken sind ohne Information. "1" ist entspricht einem dicken Strich und "0" einem dünnen. Das Dickenverhältnis ist etwa 2:1 .. 3:1. Die Wertigkeiten sind 1, 2, 4, 7, Parität, wobei Start, Stop und 0 Ausnahmen sind. Der 2/5-interleaved Code (überlappend) wurde 1972 für eine größere Dichte entwickelt und ist in ANSI MH 10.8-1983 genormt. Weil alle Lücken eine Information tragen, muß die Toleranz beachtet werden. Die 1. Ziffer wird mit Strichen die nächste mit Lücken dargestellt, usw..
Der Code 39 wurde 1974 von der Firma Intermec entwickelt um alpha-numerische Recheneingaben mit Strichcode zu ermöglichen. Dieser Code ist selbstprüfend und hat eine starke Verbreitung bei Behörden, Industrie und Handel erreicht und ist unter MIL-STD-1189 und ANSI MH 10.8 M-1983 genormt.
Der Zeichensatz besteht aus 43 Zeichen. Jedes Zeichen besteht aus 9 Elementen (5 Striche S1, S2, S3, S4, S5 und 4 Lücken L1, L2, L3, L4). Von den 9 Elementen sind 3 breit und 6 schmal. "1" bedeutet "dick". Start- und Stop-Zeichen werden mit "*" realisiert. Die Summe aller Zeichen modulo 43 ergibt die angehängte Prüfziffer.
| Strichcode 39 | |
| 01234567890123456789012345678901234567890123 | |
| 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ-.b*$/+% | |
| S1 | 01010100101010100100101010010010101001000000 |
| L1 | 00000000000000000000000000000011111111111110 |
| S2 | 00110010010110010010011001001001100100100000 |
| L2 | 11111111110000000000000000000000000000001101 |
| S3 | 10001110000001110001000011000100011100010000 |
| L3 | 00000000001111111111000100000000000000001011 |
| S4 | 10000001110000001111000000111100000011110000 |
| L4 | 00000000000000000000111111111100000000000111 |
| S5 | 01101001001101001000110100100011010010000000 |
| 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ-.b*$/+% | |
Der Code 39 wurde auf den vollständigen ASCII-Code erweitert. Die Firma Intermec hat den Code 39 verdichtet und Code 93 genannt.
Beim 3-Exzess und Aiken-Code sind die Codewörter i und (9 -i) zueinander komplementär (bitweises NOT), d.h. NOT i = 9 - i. Der Aiken - Code ist für die vorzeichenbehaftete Addition und Subtraktion geeignet.
Der Glixon -, Gray - und O`Brien - Code sind einschrittig, d.h. beim Übergang zur nächsten Zahl änder sich nur ein Bit. Beim Glixon - Code auch beim Übergang von 9 nach 0.
Der Gray - Code wird nicht als BCD - Code verwendet, weil zwischen 9 und 0 die Hamming - Distanz 3 ist.
Der Gray - Code wird häufig bei der Umwandlung analoger Größen in binäre Zeichen verwendet.
Der Gray - Code ist ein einschrittiger Code, weil beim Übergang zu einer benachbarten Zahl
lediglich ein Bit geändert wird.
Beispiel:
Die Bitfolge x gibt eine Folge von 0 und 1 an. Wir markieren in dieser Bitfolge
eine Änderungen von 0 nach 1 mit "+" und von 1 nach 0 mit "-". Dies entspricht
einer positiven bzw. negativen Flanke. Findet keine Änderung statt, so schreiben
wir 0. Diese Folge von "+", "-", "0" bezeichnen wir als Differenz - Folge.
Nun ersetzen wir sowohl "+" als auch "-" durch 1 und erhalten den Gray - Code.
| Bitfolge x | 0 1 1 0 0 1 1 1 0 1 0 0 0 1 0 1 1 1 0 1 |
| Änderung | + 0 - 0 + 0 0 - + - 0 0 + - + 0 0 - + |
| Gray - Code | 0 1 0 1 0 1 0 0 1 1 1 0 0 1 1 1 0 0 1 1 |
Um Buchstaben, Ziffern, Satz- und Sonderzeichen zu codieren sind spezielle Codes entwickelt worden:
- Morse - Code (gemäß Buchstabenhäufigkeit),
- Fernschreiber - Code (CCITT Nr.2, 5 Bits mit 2 Umschaltzeichen A:=11111 und 1:=11011),
- EBCDI - Code (Extended Binary Coded Decimals Interchange Code, 8 Bit, wird in kommerziellen Anlagen verwendet).
- ASCII-Code (CCITT Nr.5, 7 Bits, wird oft auf 8 Bits erweitert),
- Unicode (erweiterter ASCII-Code auch für asiatische Schriften).
Die Abkürzung ASCII steht für American Standard Code for Information Interchange. Dabei handelt es sich um einen in den USA normierten Code zur Darstellung von alphanumerischen Zeichen. Damit eine Modem-Rechner-Kopplung gesteuert werden kann, enthält der Code auch "nicht-druckbare" Steuerzeichen. Ursprünglich benutzte der Code 7-Bit für die Codierung. Dies ermöglicht 27 = 128 verschiedene Zeichen. Die Erweiterung auf 8 Bits (256 verschiedene Zeichen) wird unterschiedlich verwendet:
- für zusätzliche Text-Bildschirm-Sonderzeichen oder
- zur Darstellung länderspezifischer Zeichen (z.B. ä, ö, ü, Ä, Ö, Ü, ß, usw.) oder
- für eine Prüfsumme
Der ASCII-Code ist ein (immer noch oft verwendeter) Standardcode zur Speicherung von unformatierten Textdateien.
Die Abkürzung EBCDIC steht für Extended Binary Coded Decimal Interchange Code). Der EBCDIC wird häufig bei Großrechnern (z.B. für die Codierung von Magnetbändern) verwendet. Es existiert eine einheitliche Version, die 1965 von IBM eingeführt wurde. Zur Zeit geht der Trend zu 16-Bit-Codierungen von Texten (UNICODE). Damit wird ein Code für alle Sprachen, insbesondere diejenigen, die auf Silben oder Wortdarstellung beruhen (chinesisch, japanisch ...), möglich.
Eine verbreitete Zuordnung für Zeichen ist der ISO-7-Bit-Code (1967 von der ISO angenommen), der aus Vorarbeiten der C.C.I.T.T. (Comité Consultatif International Télégraphique et Téléphonique), der ECMA (European Computer Manufacturers Association) und der USASI früher und der ASA (American Standards Association) entstand. Verwendete Namen sind:
- ASCII-Code (American Standard Code for Information Interchange) oder
- ECMA-Code,
- ISCII-Code (International Standard Code for Information Interchange)
!"#$&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxuz{|}~
| hex | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | nul | soh | stx | etx | eot | enq | ack | bel | bs | tab | lf | vt | ff | cr | so | si |
| 1 | dle | dc1 | dc2 | dc3 | dc4 | nak | syn | etb | can | em | sub | esc | fs | gs | rs | us |
| 2 | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | e | s | t | u | v | w | x | y | z | { | | | } | ~ | del |
| dec | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | nul | soh | stx | etx | eot | enq | ack | bel | bs | tab |
| 1 | lf | vt | ff | cr | so | si | dle | dc1 | dc2 | dc3 |
| 2 | dc4 | nak | syn | etb | can | em | sub | esc | fs | gs |
| 3 | rs | us | ! | " | # | $ | % | & | ' | |
| 4 | ( | ) | * | + | , | - | . | / | 0 | 1 |
| 5 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; |
| 6 | < | = | > | ? | @ | A | B | C | D | E |
| 7 | F | G | H | I | J | K | L | M | N | O |
| 8 | P | Q | R | S | T | U | V | W | X | Y |
| 9 | Z | [ | \ | ] | ^ | _ | ` | a | b | c |
| 10 | d | e | f | g | h | i | j | k | l | m |
| 11 | n | o | p | q | e | s | t | u | v | w |
| 12 | x | y | z | { | | | } | ~ | del |
Zum Umwandeln von ASCII nach EBCDIC und von EBCDIC nach ASCII werden Code-Tabellen verwendet:
/* ASCII to EBCDIC translate table (only UGL character set) */
char a_to_e_tab[] = {
"\x00\x01\x02\x03\x37\x2D\x2E\x2F\x16\x05\x15\x0B\x0C\x0D\x0E\x0F" /* 00-0F */
"\x10\x11\x12\x13\x3C\x3D\x32\x26\x18\x19\x3F\x27\x22\x1D\x35\x1F" /* 10-1F */
"\x40\x5A\x7F\x7B\x5B\x6C\x50\x7D\x4D\x5D\x5C\x4E\x6B\x60\x4B\x61" /* 20-2F */
"\xF0\xF1\xF2\xF3\xF4\xF5\xF6\xF7\xF8\xF9\x7A\x5E\x4C\x7E\x6E\x6F" /* 30-3F */
"\x7C\xC1\xC2\xC3\xC4\xC5\xC6\xC7\xC8\xC9\xD1\xD2\xD3\xD4\xD5\xD6" /* 40-4F */
"\xD7\xD8\xD9\xE2\xE3\xE4\xE5\xE6\xE7\xE8\xE9\xAD\xE0\xBD\x5F\x6D" /* 50-5F */
"\x79\x81\x82\x83\x84\x85\x86\x87\x88\x89\x91\x92\x93\x94\x95\x96" /* 60-6F */
"\x97\x98\x99\xA2\xA3\xA4\xA5\xA6\xA7\xA8\xA9\xC0\x4F\xD0\xA1\x07" /* 70-7F */
"\x43\x20\x21\x1C\x23\xEB\x24\x9B\x71\x28\x38\x49\x90\xBA\xEC\xDF" /* 80-8F */
"\x45\x29\x2A\x9D\x72\x2B\x8A\x9A\x67\x56\x64\x4A\x53\x68\x59\x46" /* 90-9F */
"\xEA\xDA\x2C\xDE\x8B\x55\x41\xFE\x58\x51\x52\x48\x69\xDB\x8E\x8D" /* A0-AF */
"\x73\x74\x75\xFA\x15\xB0\xB1\xB3\xB4\xB5\x6A\xB7\xB8\xB9\xCC\xBC" /* B0-BF */
"\xAB\x3E\x3B\x0A\xBF\x8F\x3A\x14\xA0\x17\xCB\xCA\x1A\x1B\x9C\x04" /* C0-CF */
"\x34\xEF\x1E\x06\x08\x09\x77\x70\xBE\xBB\xAC\x54\x63\x65\x66\x62" /* D0-DF */
"\x30\x42\x47\x57\xEE\x33\xB6\xE1\xCD\xED\x36\x44\xCE\xCF\x31\xAA" /* E0-EF */
"\xFC\x9E\xAE\x8C\xDD\xDC\x39\xFB\x80\xAF\xFD\x78\x76\xB2\x9F\xFF" /* F0-FF */
};
/* EBCDIC to ASCII translate table (only UGL character set) */
char e_to_a_tab[] = {
"\x00\x01\x02\x03\xCF\x09\xD3\x7F\xD4\xD5\xC3\x0B\x0C\x0D\x0E\x0F" /* 00-0F */
"\x10\x11\x12\x13\xC7\x0A\x08\xC9\x18\x19\xCC\xCD\x83\x1D\xD2\x1F" /* 10-1F */
"\x81\x82\x1C\x84\x86\x0A\x17\x1B\x89\x91\x92\x95\xA2\x05\x06\x07" /* 20-2F */
"\xE0\xEE\x16\xE5\xD0\x1E\xEA\x04\x8A\xF6\xC6\xC2\x14\x15\xC1\x1A" /* 30-3F */
"\x20\xA6\xE1\x80\xEB\x90\x9F\xE2\xAB\x8B\x9B\x2E\x3C\x28\x2B\x7C" /* 40-4F */
"\x26\xA9\xAA\x9C\xDB\xA5\x99\xE3\xA8\x9E\x21\x24\x2A\x29\x3B\x5E" /* 50-5F */
"\x2D\x2F\xDF\xDC\x9A\xDD\xDE\x98\x9D\xAC\xBA\x2C\x25\x5F\x3E\x3F" /* 60-6F */
"\xD7\x88\x94\xB0\xB1\xB2\xFC\xD6\xFB\x60\x3A\x23\x40\x27\x3D\x22" /* 70-7F */
"\xF8\x61\x62\x63\x64\x65\x66\x67\x68\x69\x96\xA4\xF3\xAF\xAE\xC5" /* 80-8F */
"\x8C\x6A\x6B\x6C\x6D\x6E\x6F\x70\x71\x72\x97\x87\xCE\x93\xF1\xFE" /* 90-9F */
"\xC8\x7E\x73\x74\x75\x76\x77\x78\x79\x7A\xEF\xC0\xDA\x5B\xF2\xF9" /* A0-AF */
"\xB5\xB6\xFD\xB7\xB8\xB9\xE6\xBB\xBC\xBD\x8D\xD9\xBF\x5D\xD8\xC4" /* B0-BF */
"\x7B\x41\x42\x43\x44\x45\x46\x47\x48\x49\xCB\xCA\xBE\xE8\xEC\xED" /* C0-CF */
"\x7D\x4A\x4B\x4C\x4D\x4E\x4F\x50\x51\x52\xA1\xAD\xF5\xF4\xA3\x8F" /* D0-DF */
"\x5C\xE7\x53\x54\x55\x56\x57\x58\x59\x5A\xA0\x85\x8E\xE9\xE4\xD1" /* E0-EF */
"\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\xB3\xF7\xF0\xFA\xA7\xFF" /* F0-FF */
};
void ascii_from_ebcdic(BYTE * pByt, UINT nByt) {
for (UINT i = 0; i < nByt; i++)
pByt[i] = e_to_a_tab[ (UINT)pByt[i] ];
}
E-Mail werden mittels binären Dateien übertragen. Die MIME-Codierung beruht aus RFC 2045. Die Base-64-Zeichen bilden Zeilen mit (max) 76 Zeichen je Zeilen (windows-typischer "\r "-Umbruch, Unix-typischer " "-Umbruch).
<img alt='fh-logo-klein' src='data:image/gif;base64, R0lGODlhFgAUAPcAAP//////zP//mf//Zv//M///AP/M///MzP/Mmf/MZv/MM//MAP+Z//+ZzP+Z mf+ZZv+ZM/+ZAP9m//9mzP9mmf9mZv9mM/9mAP8z//8zzP8zmf8zZv8zM/8zAP8A//8AzP8Amf8A Zv8AM/8AAMz//8z/zMz/mcz/Zsz/M8z/AMzM/8zMzMzMmczMZszMM8zMAMyZ/8yZzMyZmcyZZsyZ M8yZAMxm/8xmzMxmmcxmZsxmM8xmAMwz/8wzzMwzmcwzZswzM8wzAMwA/8wAzMwAmcwAZswAM8wA AJn//5n/zJn/mZn/Zpn/M5n/AJnM/5nMzJnMmZnMZpnMM5nMAJmZ/5mZzJmZmZmZZpmZM5mZAJlm /5lmzJlmmZlmZplmM5lmAJkz/5kzzJkzmZkzZpkzM5kzAJkA/5kAzJkAmZkAZpkAM5kAAGb//2b/ zGb/mWb/Zmb/M2b/AGbM/2bMzGbMmWbMZmbMM2bMAGaZ/2aZzGaZmWaZZmaZM2aZAGZm/2ZmzGZm mWZmZmZmM2ZmAGYz/2YzzGYzmWYzZmYzM2YzAGYA/2YAzGYAmWYAZmYAM2YAADP//zP/zDP/mTP/ ZjP/MzP/ADPM/zPMzDPMmTPMZjPMMzPMADOZ/zOZzDOZmTOZZjOZMzOZADNm/zNmzDNmmTNmZjNm MzNmADMz/zMzzDMzmTMzZjMzMzMzADMA/zMAzDMAmTMAZjMAMzMAAAD//wD/zAD/mQD/ZgD/MwD/ AADM/wDMzADMmQDMZgDMMwDMAACZ/wCZzACZmQCZZgCZMwCZAABm/wBmzABmmQBmZgBmMwBmAAAz /wAzzAAzmQAzZgAzMwAzAAAA/wAAzAAAmQAAZgAAMwAAAP///wAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACH5BAEAANgALAAAAAAWABQA AAivAAEIHEiwoMGDA/0IVIgQoR9pAqUxbEjwIYAlbwBII0QxoURKuXJR8oMKVUc/rlC5AvCGUoCS EhuiZOaKmR8DAEimjGnwoUpU0lQMlPaT50AqRFExC0pQBdGnE326mjrxaMqdDJGmZIaqqkAqNGka BUvUFdOBTlMC9Yq0JFCCSaUZJaj1p0BCRb3SfcqSEgCYegsi9UOpUq43KAP3hNhSo+KDWkw67miQ ykLKmA0GBAA7=' />
// Pseudo-Code //////////0123456789012345678901234567890123456789012345678901234567890123 var s64='ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'; var f64 = new Array(256); // inverse Tabelle for (var i=0; i < s64.length ;i++) f64[s64.charCodeAt(i)] = i; s64.charCodeAt(1) ergibt 66 f64[66] ergibt 1
Ein binärere Bytestrom (jeweils 8-bit) wird in den 64 Zeichen (Base-64-Zeichen, 6 Bit je Zeichen) codiert (3-to-4 encoding).
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'; und hinzu kommt das '="-Zeichen als Endekennung (Padding). Der Datenstrom endet mit einem Vielfachen 6 (auffüllen mit 0-en und '=' anhängen).
|
3 Byte zu je 8 Bit = 24 Bit (Src-Eingabe) |
|........|.... ....|........| 3 Byte |
|
4 Base64 zu je 6 Bit = 24 Bit (Base64-Ausgabe) |
|......|......|......|......| 4 Byte |
|
Base64-Ende mit Padding:
falls (Src.length % 3 == 1): Base64-Ausgabe erhält 2 angefügte '0' falls (Src.length % 3 == 2): Base64-Ausgabe erhält 1 angefügte '0' falls (Src.length % 3 == 0): Base64-Ausgabe erhält 0 angefügte '0' danach noch 1 zusätzlich angefügtes '=' |
|
Für die Darstellung von Zeichen auf dem Bildschirm kann der Bitmap-Code verwendet werden. Bei einer Bitmap-Rastergrafik hat jedes Zeichen ( hier der Buchstabe A) gleichviele Bits. Die Zeichen werden in einer Zeichen-Tablelle abgelegt ( A, B, C, ..., usw. ). Der Tabellen-Index ( Ordinalzahl ) entspricht hier dem ASCII-Code. Die Bits für das Zeichen "A" beginnen mit dem 65. Tabellen-Eintrag. Ein darzustellendes Zeichen wird ähnlich einem "Stempel-Verfahren" in den Bildschirmspeicher kopiert.
Bits 00 .. 07 hex Wert = 00 Bits 08 .. 15 hex Wert = 01 Bits 16 .. 23 hex Wert = 82 Bits 24 .. 31 hex Wert = 24 Bits 32 .. 39 hex Wert = c7 Bits 40 .. 47 hex Wert = 24 Bits 48 .. 55 hex Wert = 00 Bits 56 .. 63 hex Wert = 00
Ein gespeichertes Maschinenprogramm besteht aus einer Folge von Bitmustern. Der Reihe nach holt sich der Prozessor das nächste Bitmuster (den nächsten Befehl). Ein Befehl für den Prozessor ist ein Bitmuster, das der Prozessor interpretiert ("versteht").
Ein Programm erstellen heißt, für den Prozessor die richtige Folge von Bitmuster-Befehlen erstellen und speichern.
Das Bitmuster für ca. 100 OpCode-Befehle sind unübersichtlich.
Jedem Bitmuster des Maschinen-Befehlsvorrates wird ein lesbares Kurzwort (OpCode, Assembler-Befehl) zugeordnet. Zu jedem Befehl in Assembler gehört ein Mikroprozessor-Befehl. Jede Prozessorfamilie hat eigene Bit-Befehlsmuster und somit eigene Assembler-Befehle.
Ein Mnemonik ist die Bezeichnung des in Assembler verwendeten Ein Befehlskürzels (meist 3 bis 4 Zeichen) beschreibt die Prozessor-Operation eines Maschinen-Befehls und wird auch als Mnemonik bezeichnet.
Ein moderner Computer ist ein komplexes System von Komponenten. Diese tauschen mit elektrischen Signalen Informationen aus. Um die grundlegenden Funktionen zu verstehen, benötigen wir ein einfaches Modell. Ein grundlegendes Modell besteht aus Prozessor, Speicher und allen anderen Komponenten. Auch der Prozessor enthält einige, wenige, interne Speicher (Register). Die Prozessor - Befehle stehen als Bitmuster im Speicher und bilden das Maschinen - Programm. Eine Maschinen - Befehl kann nur vom Prozessor ausgeführt werden.
Ein Programm wird ausgeführt, wenn nacheinander Maschinen - Befehle (OpCode) von Speicher zum Prozessor geschickt werden und der Prozessor diese Befehle ausführt. Das Programm bleibt im Speicher erhalten. Auf die Leitungen (Datenbus) zwischen Speicher und Prozessor wird immer eine Kopie des OpCodes gelegt. Wurde ein Befehl ausgeführt (interpretiert), so holt sich der Prozessor den nächsten Befehl aus dem Speicher. Die Prozessor - Frequenz und Bus - Frequenz bestimmen die Geschwindigkeit der Befehls - Ausführung und Befehls - Übertragung.
| Enviroment | Prozessor | Speicher |
Die Assemblerbefehle sind einfach aufgebaut. Beim Intel 80x86 kann ein Assemblerbefehl durch folgendes Schema beschrieben werden:
| [Präfix] | Mnemonik | [Operand 1] | [, Operand 2] |
- Der Maschinencode bildet ein Maschinenprogramm
- Der Maschinencode steuert den Prozessor
- Der Maschinencode besteht aus OpCode
- An dem Bitmuster des OpCode erkennt der Prozessor den Befehl
-
Der OpCode wird mit Binärziffern (Bin : 0, 1)
oder Hexa- Dezimal - Ziffern (Hex : 0, 1, 2, ..., 9, A, B, C, D, E, F)
angegeben.
Soll in das AX - Register des Prozessors eine 10 geschieben werden, so muß das Bitmuster "1011 1000 1010 000 000 000" (bzw. die Hex-Zahlen "B8 0A 00" mit einem Hex nach Binär - Wandlung) im Speicher hinterlegen werden. Es wird ein Übersetzungsprogramm (Assembler) benutzt, das die Mnemoniks in das Bitmuster umwandelt. In Assembler-Quelltext wird z.B. "MOV AX, 0Ah" geschrieben. Mit Hilfe eines Übersetzungsprogrammes (Assembler) wird diese (dem Menschen eher verständliche Kurz-) Schreibweise in ein Bitmuster umgewandelt, das von dem Prozessor "verstanden" wird. Ein solches kurzes Bitmuster im Speicher (Maschinenprogramm) hat z.B. die folgende Darstellung, wobei beim Assembler-Programm die Mnemonics benutzt werden:
| Programm in Speicher (RAM) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Bin: | 0001 1110 | 1011 1000 | 0000 0000 | 0000 0000 | 0101 0000 | 1111 1100 | 1000 1100 | 1100 1000 |
| Hex: | 1E | B8 | 00 | 00 | 50 | FC | 8C | C8 |
| Mnemonics: | PUSH DS | MOV AX, 0 | PUSH AX | CLD | MOV AX, CS | |||